Message Prioritization in Kafka
Hello there! If you’re familiar with Kafka. And if you understand the internals, then you might wonder how to implement message prioritization in Kafka. Because, the way it works, this use case is simply not directly possible with Kafka. If you are actually new to Kafka, then be sure to stick with me till the end of the article. I’ll try my best to share my knowledge on how Kafka works and the various ways to implement message prioritization in Kafka.
The Basics:
Don’t skip this part if you want to understand why I mentioned it is not directly possible to implement prioritization!
Kafka: Some of you might see Kafka as a message queuing system. Trust me, I also did initially. But, that’s not entirely true. Kafka is a message streaming platform that is horizontally scalable. It is majorly used for stream processing use-cases. Also, being used as a message-bus in applications that are designed based on publisher-subscriber pattern (often referred to as a pub-sub model) or event-driven architecture.
Okay, let’s talk about the internals of Kafka, and let me explain how it stores the messages.
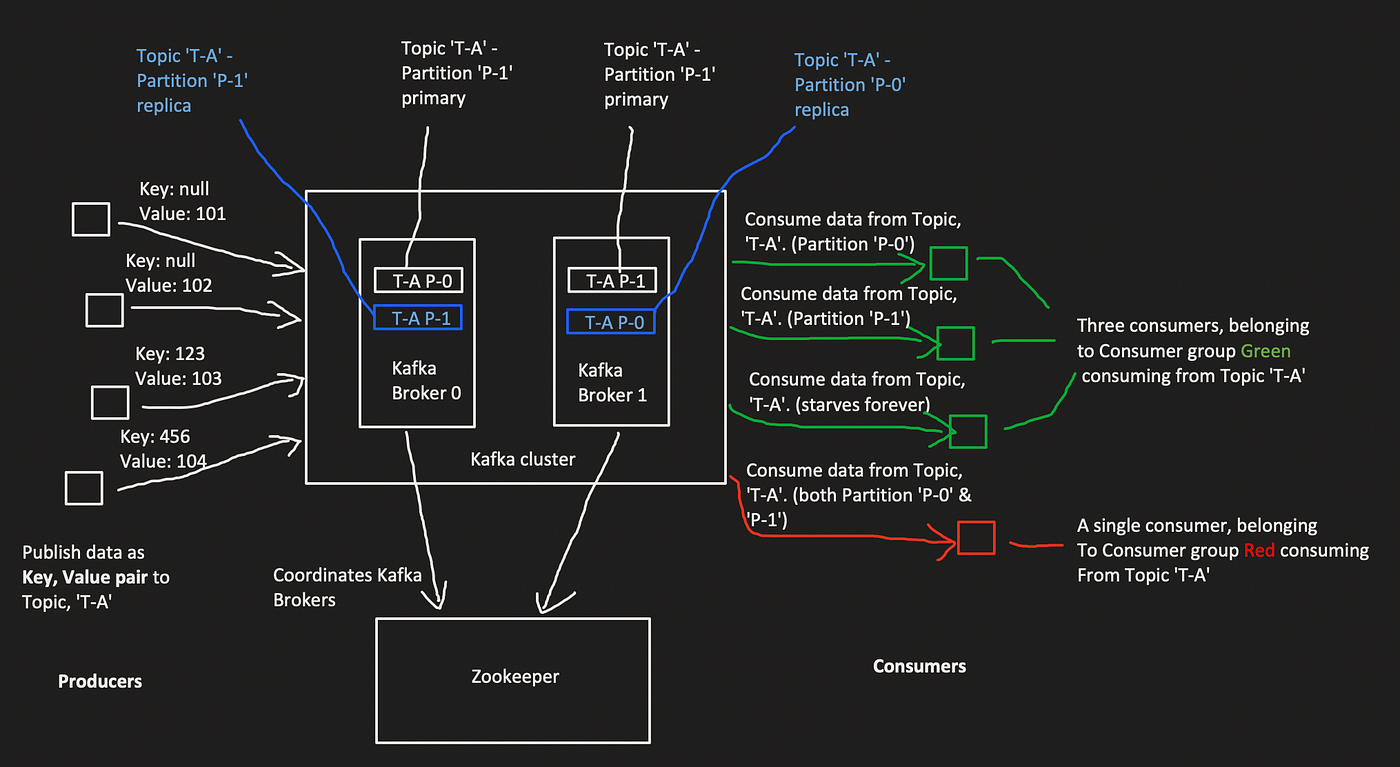
Kafka Brokers: Kafka broker is a single Kafka node holding topics and partitions. In a cluster, multiple Kafka brokers share the load and enable resiliency if one of the brokers goes down.
Zookeeper: Zookeeper acts as service discovery for a Kafka cluster. It coordinates with various Kafka brokers and keeps them in sync whenever a new topic is created, deleted, a broker joins the cluster, and when a broker goes down. Also, helps in leader election when a node goes down.
Topics: Topics are similar to message queues. It holds messages related to a given topic. All the messages are either published to a given topic or consumed from a given topic. There can be multiple producers to a given topic and, there can be various consumers for a given topic. Each topic is a single and logically distributed commit log of messages. A replication factor can also be provided while creating the topic. This determines the replication of each partition under the topic. The replication factor can be at most equal to the number of Kafka brokers in your cluster. This improves the resiliency in case a Kafka broker goes down.
Replication Factor of a topic ≤ Number of Kafka brokers in the cluster
Partitions: A topic is split into multiple partitions. The number of partitions can be specified while creating the topic. Also, the number can be modified for an existing topic. A partition is nothing but an append-only file that is physically stored in the file system. You can think of it as a log file where each line is a message and, the file will be only appended on each incoming message.
These messages are immutable. Meaning, once a message is sent to a topic, you cannot basically go and edit or delete a specific message. Insertion of messages in the middle is also not possible since it is an append-only file. That means reordering messages in Kafka is impossible.
Now you might understand the real reason behind why prioritization is not a built-in feature in Kafka. However, we can achieve it in various ways. But we’ll come to it later and, let’s complete the basics first. Coming back to partitions. Every single message sent to a topic will be internally sent to only one of its partitions. While consuming from a topic, it’s the consumer’s responsibility to consume from various partitions. This means FIFO ordering of message is only guaranteed at partition-level and not at topic-level.
Messages: Kafka expects an optional key with every single message that we send to a topic. This key will be hashed to identify the partition the message is going to fall into. Make sure to choose a proper field as the key. If not chosen properly, then some of the partitions might stay empty while the others are filled with tons of messages. If the key is not provided, then Kafka routes it to a partition based on a round-robin fashion. Also, the messages are retained in the respective partition for a maximum of 7 days. This retention time can be modified by modifying the retention config retention.ms for a given topic.
Partition Number = hash(Key) % (Number of partitions available for the topic)
Consumers & Consumer Groups: Since Kafka is not a message queuing system, the consumer must choose whether to read from the earliest or latest offset from a given topic. This can be set using a property on Kafka client, auto.offset.reset. This provides us the control when a consumer starts at the very first time, whether to start consuming from the first message that is retained for a topic or to start consuming from the most recent message received. Kafka maintains the offsets of each consumer to partition. Consumer clients will choose to commit either asynchronously or synchronously after each set of messages is received. Consumer clients can even choose to commit after processing the message, allowing Kafka broker to resend the message in case of processing failure at the client end. To allow load sharing from a consumer perspective for a given topic, Kafka allows consumer groups. The consumer group is a unique identification for a group of instances belonging to a same service. Kafka stores the consumer group’s offset even if all the consumers of a given group go down. This allows the consumer group to start processing from where it left off when coming back online.
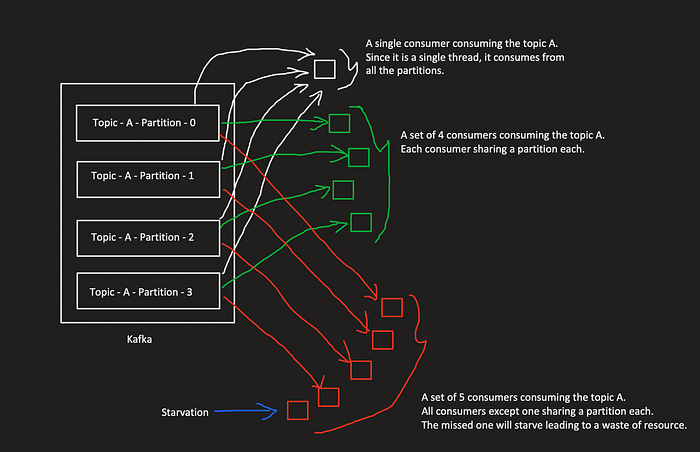
How consumer groups shares the load? In a consumer group, at least one partition is assigned per consumer in a way that no two consumers are consuming the same partition. Make sure to use the number of consumers less than or equal to the partitions provided in the topic. If the number of consumers equals the partitions then each consumer will be assigned a partition each. So, if there are more consumers than the number of partitions, then they will be infinitely starving causing a waste of resources.
Note: Partition assignment for consumers is by default managed by Kafka itself. So, the consumer group clients don’t have to worry about the same. When a consumer in a consumer group goes down, the partition(s) it was listening to, will be shared across other consumers (if any) in the same consumer group.
Now that you understand the basics required. Let’s jump into the topic.
Ways to prioritize messages in Kafka
#1 The Brute-force Way:
The easiest way to solve this problem is to create separate topics for each priority. From the producer’s perspective, we can write a logic to publish to the respective topic based on priority logic. From the consumer perspective, we can write a code to listen to the highest priority topic first and process until there are no messages. Then, we can fall back to the lower priority queue and so on.
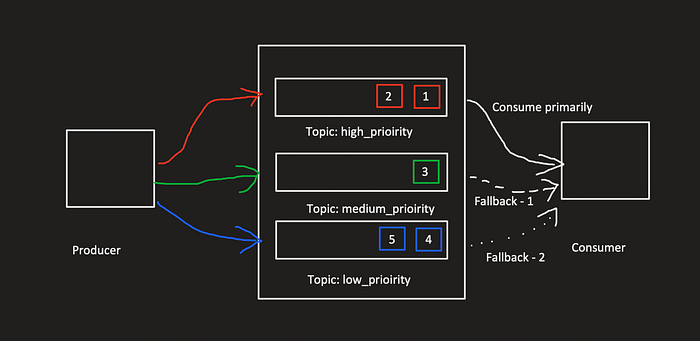
Here’s the Java (Spring) implementation for the consumer logic.
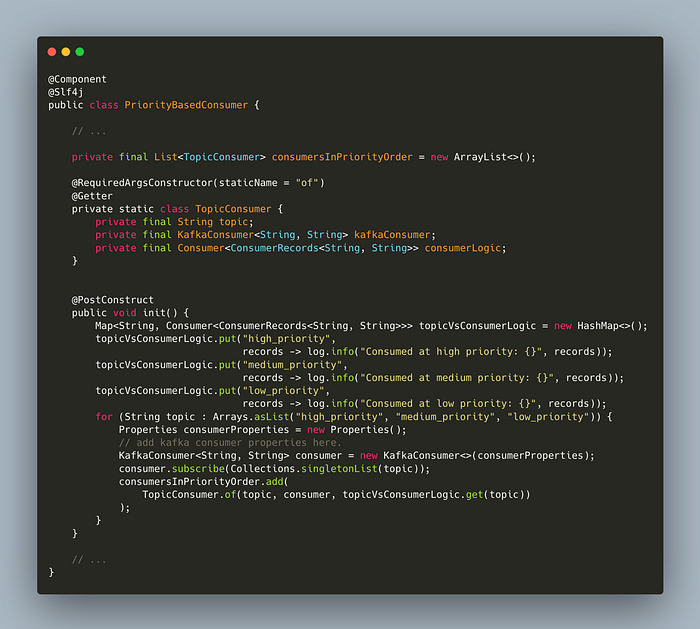
I have initialized the class with a PostConstruct method that will be executed once the object is created by the Spring during start-up. If you don’t understand this. It is very similar to a constructor. In this case, once the object is initialized, this method will be triggered and executed. We are initializing the List<TopicConsumer> in a way that high priority topic consumer comes first, then to medium, and then to low.
Now, as the next step. I’ve created a consumer, which will be started when the application is ready.
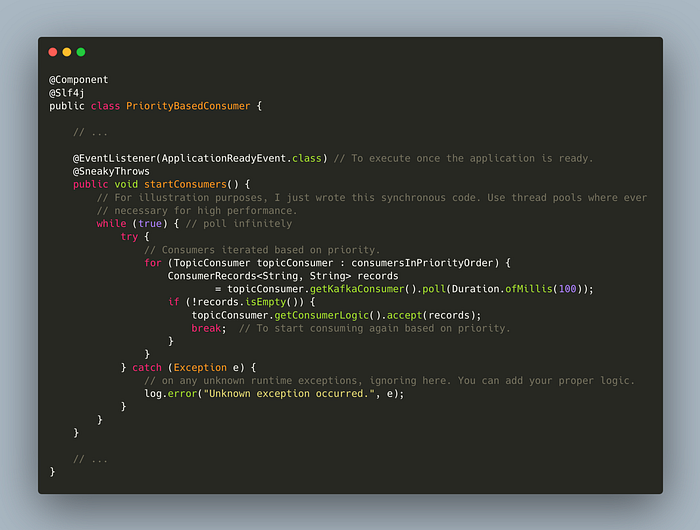
Here, we are consuming infinitely in a way that we are checking the top priority topic every time if there are any messages. This way, prioritization can be implemented from the consumer perspective.
You can check out the code for the above implementation in this GitHub repository.
This implementation is buggy. If the high-priority topic always has some message, then the consumer will not consume other priority topics. But there is a better implementation of similar logic available here in priority-kafka-client under Flipkart’s Incubator. Do check out their documentation!
#2 The Resequencer Pattern:
This is a message routing design pattern that helps to solve our prioritization problem. A resequencer is a custom component that receives a stream of messages that may not arrive in order. It has an internal buffer to store a set of messages and also has the logic to sort the message and publish the same to the output channel.

Unlike the first approach, we use a single topic here. This pattern can be implemented by introducing a service in the middle between publisher and consumer. This service consumes the Kafka topic containing the messages to be prioritized. This service is responsible to handle a predefined buffer of messages. Sorting should be applied when the number of messages reaches a given capacity. A timeout must also be supported in case we are not receiving the required capacity of messages. Once sorting is applied, all the messages in the buffer will be published to the outgoing channel. This outgoing channel topic can be consumed by our actual consumer which expects the prioritized messages first.
I have utilized Spring Boot Apache Camel’s Resequence to implement the following Kafka integration.
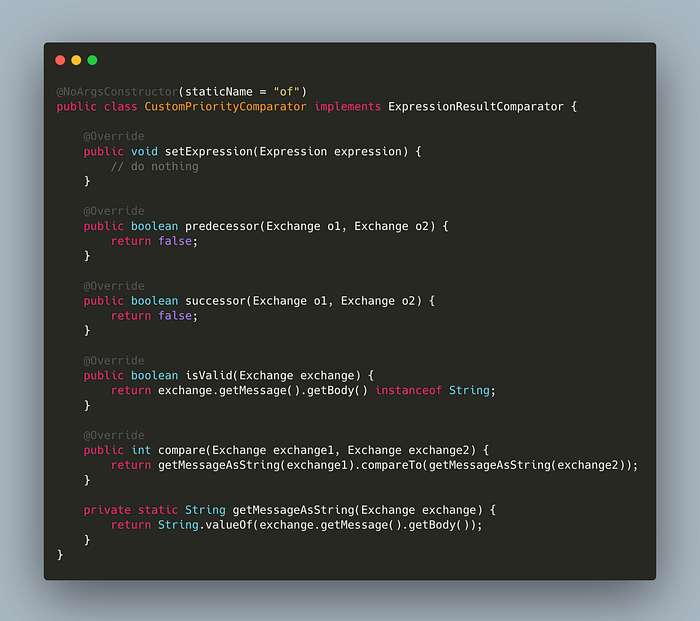
We need to implement an ExpressionResultComparator, which can be later utilized when creating a Camel Route. If you are entirely new to this. Don’t worry and just focus on the compare method. We are just getting the message and comparing it based on String’s compareTo method. That means, whatever we send in, we will be expecting the output to be in alphabetical order.
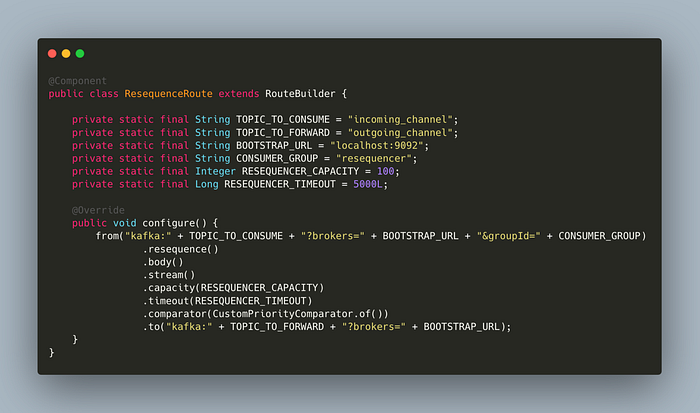
In the above class, we are configuring a route that is starting from the topic incoming_channel and ends at the topic outgoing_channel . We are also applying a resequence with a buffer capacity of 100 and a timeout of 5000 milliseconds.
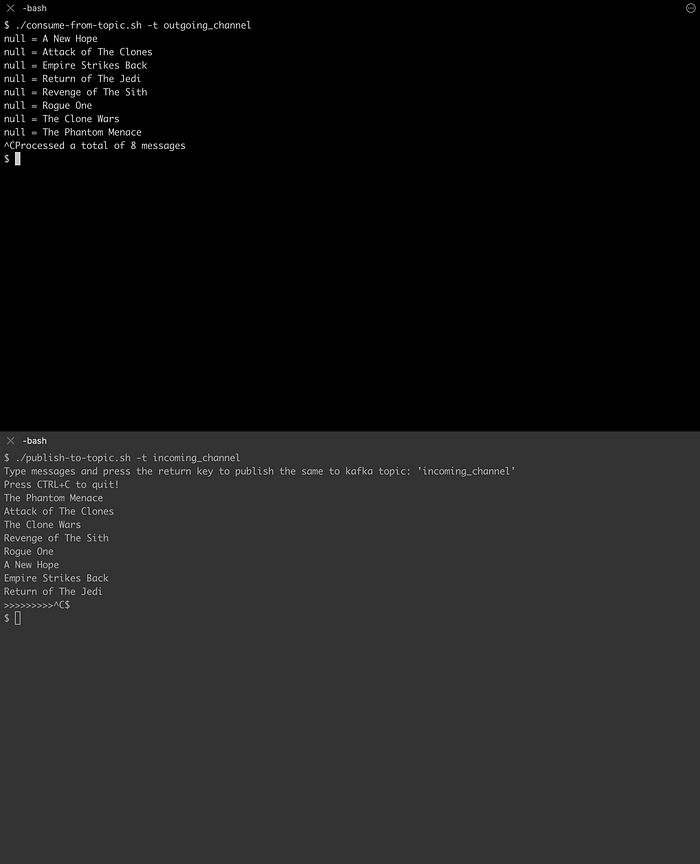
You can find this code implementation available in this GitHub repository.
This pattern is not the best solution available out there for prioritizing the messages. Here’s why. As per the pattern, the resequencer was supposed to collect the messages until it reaches a condition. This condition can be met either when the buffer reaches the max capacity or when the specified time runs out. This means there could be a delay in receiving the priority messages on the actual consumer end. Also, if we want this solution to be efficient, then we need to maximize the buffer size and reduce the time out. But that’s not the only factor for efficiency. It also depends on the incoming message throughput. This can be predicted but, we cannot be certain about this factor.
#3 The Bucket Priority Pattern
This is by far the best implementation available. This pattern depends on the topic partitions. This pattern addresses the prioritization problem by creating abstractions over given topic partitions called buckets. The buckets may contain one or more partitions. The priority of the bucket directly depends on the number of partitions falling under that bucket. Higher the number of partitions, the higher the priority of the bucket. From the basics, we know that a partition can have only one consumer from a consumer group. This means that the number of parallel consumers per bucket directly depends on the number of partitions available in that bucket. Since the top priority gets the most partitions, it also gets the most number of consumers.
Unlike the other two approaches, this pattern allows the consumers to consume all priority messages in a given time. Only the number of consumers for a given priority changes.
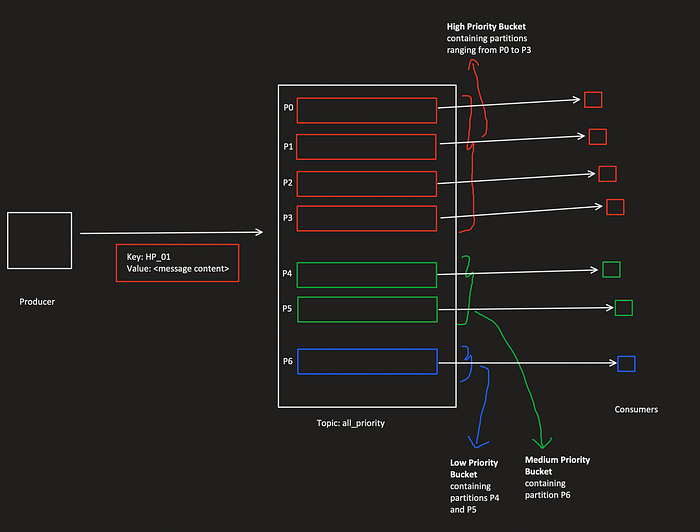
As you know, the key field in the message can be used to route it to a specific partition. From the producer’s perspective, we can route the message to a given bucket. We can expect the load-balanced consumers to consume it on respective priority.
This has been implemented by Ricardo Ferreira, and the link to the Java (Spring) implementation and the documentation is available in this GitHub repository.
Ricardo has also created a sample producer and consumer in Java which demonstrates the bucket-priority pattern. You can check that code in this GitHub repository.
References
- Bucket Priority Pattern by Ricardo Ferreira @ confluent.io & github.com
- Enterprise Integration Patterns — Resequencer
- Does Kafka support priority for topic or message? @ stackoverflow.com
- Apache Camel — Resequence
- Apache Camel — Kafka
- Priority Kafka Client under Flipkart Incubator @ github.com
